up:: RDL MOC
lecture08-part3-behaviour-trees-0.pdf
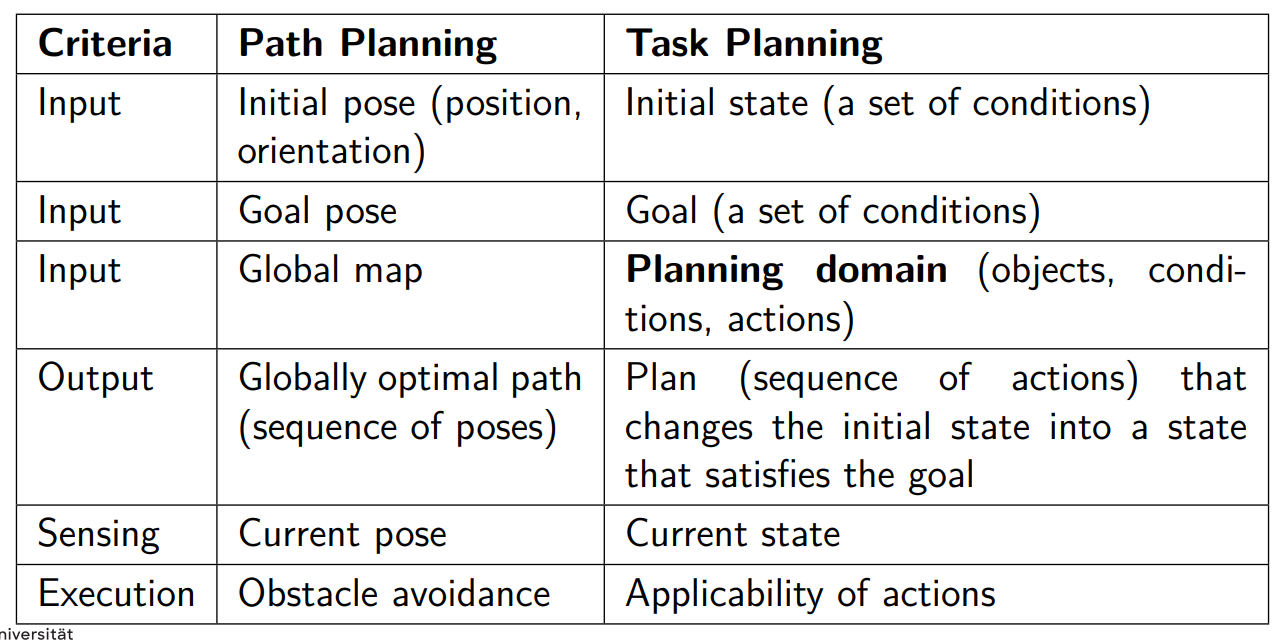
Task Planning
Example for Task Plan:
- Go to the shop.
- Select the gift.
- Purchase the gift.
- Bring the gift home.
- Pack the gift.
- Label the package.
- Bring the package to post office.
- Hand-over the package for shipment
Goal
The objective of the plan.
Can be written as condition: Gift has been send to firand.The world
Your world consists
- of yourself (the agent),
- certain objects (gift, package) and
- a set of locations (home, shop, post office).
Locations are Objects of Typ Loaction.Preconditions
Actions can be performed only in specific states that statisfy certain preconditions.
For example,
The package can be labeled only after the gift is packed.
The gift can be packed only after it has been purchased and brought home.
Summery
Link to original
- The scenario described a problem which you had to solve.
- Solving the problem was your task.
- The solution to the problem should satisfy a goal condition.
- You came up with a plan to satisfy the goal.
- The plan is a sequence of actions that can be performed in the world.
- The state describes the relevant properties of all things in the world.
- An action can be performed only if its preconditions are satisfied in the current state.
- When an action is performed, it has an effect on the state.
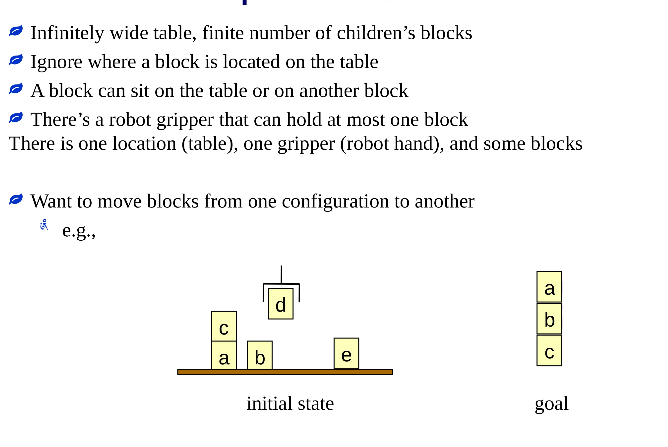
The Blocks World
lecture08-part2-task-planning-representation-algorithms-0.pdf
Constant symbols for concrete things:
The blocks: a, b, c, d, e
Predicates to represent conditions:
- ontable(x) - block x is on the table
- on(x,y) - block x is on block y
- clear(x) - block x has nothing on it
- holding(x) - the robot hand is holding block x
- handempty - the robot hand isn’t holding anything
Predicates have the form predicate-symbol(arguments).
States
a set of ground predicates
- Represents the conditions or facts that are true in that state.
- Since we have only a finite no. of predicates and a finite no. of constant symbols, we have only a finite no. of possible states.
Closed world assumption: What is not known to be true is assumed to be false.Operators
Operators are generalizations of actions.
Operator: a triple o=(name(o), precond(o), effects(o))
- precond(o): preconditions
- Predicates and their negations that must be true in order to use the operator.
- effects(o): effects
- Predicates and their negations that the operator will make true.
- name(o): a syntactic expression of the form n(x1 ,…,xk )
- n is an operator symbol - must be unique for each operator.
- (x1 ,…,xk ) is a list of every variable symbol (parameter) that appears in o.
Rather than writing each operator as a triple, we’ll usually write like this:
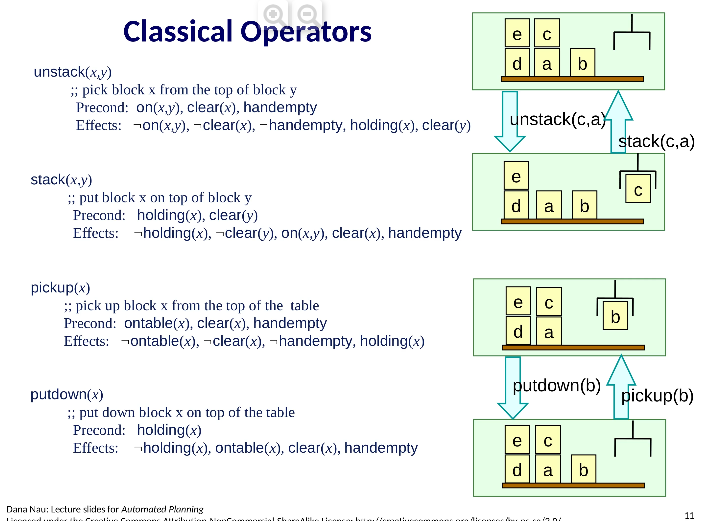
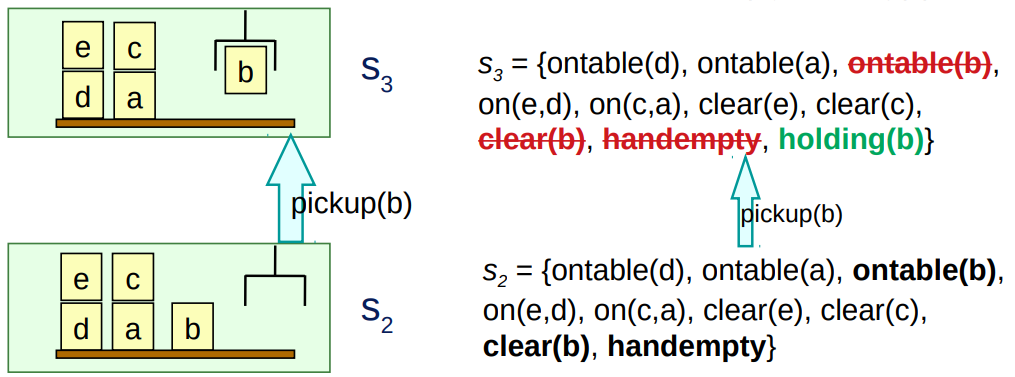
pickup(x) ;; gripper picks up block x from the top of the table Precond: ontable(x), clear(x), handempty Effects: not ontable(x), not clear(x), not handempty, holding(x)
Actions
An action is a ground instance (via substitution) of an operator
- Suppose we substitute x with b.
- Then we get the following action:
- pickup(b)
- precond: ontable(b), clear(b), handempty
- effects: not ontable(b), not clear(b), not handempty, holding(b)
i.e., The robot’s gripper picks up block b off the table.
Notation
Let a be an operator or action. Then
precond+ (a) = {predicates that appear positively in a’s preconditions}
precond– (a) = {predicates that appear negatively in a’s preconditions}
effects+ (a) = {predicates that appear positively in a’s effects}
effects– (a) = {predicates that appear negatively in a’s effects}
Example:
pickup(b) precond: ontable(b), clear(b), handempty effects: not ontable(b), not clear(b), not handempty, holding(b)
precond+ (pickup(b)) = {ontable(b), clear(b), handempty}
precond- (pickup(b)) = {}
effects+ (pickup(b)) = {holding(b)}
effects– (pickup(b)) = {ontable(b), clear(b), handempty)}
Executing an Applicable Action
Goal
a set of ground predicates or its negations
- Represents the conditions that should hold in a goal state.
- Positive goal conditions should be present in the goal state and negavite goal conditions should be absent in the goal state.
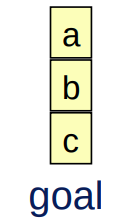
goal = {on(b,c), on(a,b)}Solutions
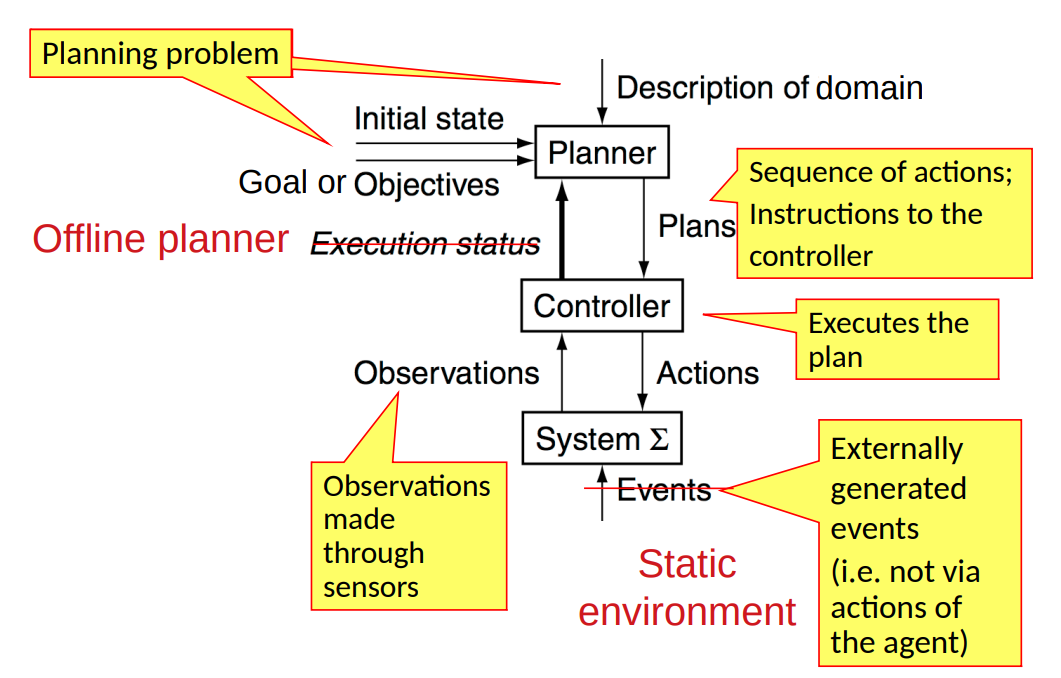
Planner
Given a planning domain and a planning problem, how can the robot autonomously find a plan, i.e. a sequence of actions, in order to go from the initial state to a state that satisfies the goal?
Algorithms that do this are called planners.Three Main Types of Planners
Domain-specific planners
- Made or tuned for a specific planning domain
- Most successful real-world planning systems work this way (Mars exploration, sheet metal bending, playing bridge, etc.)
- Won’t work well (if at all) in other planning domains
Domain-independent planners ⇒ focus of most research
- In principle, works in any planning domain
- In practice, need restrictions on what kind of planning domains it can be applied
- e.g. Classical Task Planning
Configurable planners
Link to original
- Domain-independent planning engine
- Input includes info about how to solve problems in some domain
Restrictive Assumptions in Classical Task Planning
A0: Finite system:
Finite no. of states and actions.
A1: Fully observable:
The agent always knows the current state of the world.
A2: Deterministic: Each action has only one outcome.
If an action is applied to a state, it will bring the world to a single new state.
A3: Static (no exogenous events):
Changes to the world state can be caused only through the agent‘s own actions.
A4: Attainment goals:
Goal is specified explicitly and corresponds to a set of goal states Sg .
A5: Sequential plans:
A plan is a linearly ordered sequence of actions (a1 , a2 , … an ).
A6: Implicit time:
No time durations; a linear sequence of instantaneous states and actions.
A7: Off-line planning:
Planner doesn’t know the execution status of the plan while it is generating the plan.
Link to originalPlanning is Searching…
- Nearly all planning procedures are search procedures.
- In this lecture, we will look at state-space planning, which is used by classical task planners.
Similar to path planning algorithms.
Here, each node represents a state of the world.
Finds a path that starts at the initial state and ends at a goal state.
Forward Search
Forward-search is sound
Any plan that is returned is guaranteed to be a solution
Forward-search also is complete
If a solution exists then Forward-search will return a solution.
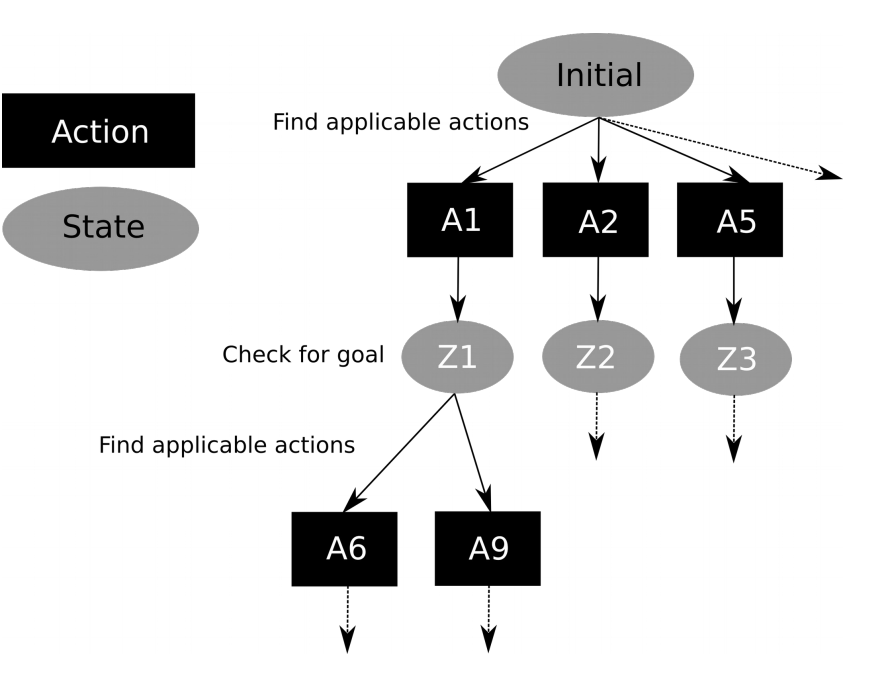
Search proceeds as follows:
- The algorithm starts the search at the initial state.
- If the initial state satisfies the goal, then search ends and we get a plan of length zero.
- If not, the algorithm applies all applicable actions to the initial state to produce new states.
- It checks if any of the new states satisfies the goal.
- If yes, search ends.
- If not, then search continues by applying actions to each of the new states.
- Search continues until either all reachable states have been examined or a goal state has been reached.
- If a goal state is reached, the algorithm returns the sequence of actions that led from the initial state to the found goal state.
Some deterministic implementations of forward search:
- breadth-first search
- best-first search (e.g., A*)
Breadth-first and best-first search are sound and complete.
- But they usually aren’t practical because they require too much memory.
- Memory requirement is exponential in the length of the solution.
Forward search can have a very large branching factor.
Link to original
- E.g., many applicable actions that don’t progress toward goal.
- Why this is bad:
- Deterministic implementations can waste time trying lots of irrelevant actions.
- Need a good heuristic function and/or pruning procedure.
Classical Planning and Acting
Summary
Link to original
- An example: Blocks world
- Classical representation of the planning domain (constant symbols, predicates, operators), states and actions.
- Applicability of an action to a state
- State transition function
- Assumptions needed for classical Task Planning
- Statement of a classical Task Planning problem
- Three types of planners: domain-dependent, domain-independent, configurable
- State-space planning: Forward Search
- Conceptual model of planning and acting (plan execution).



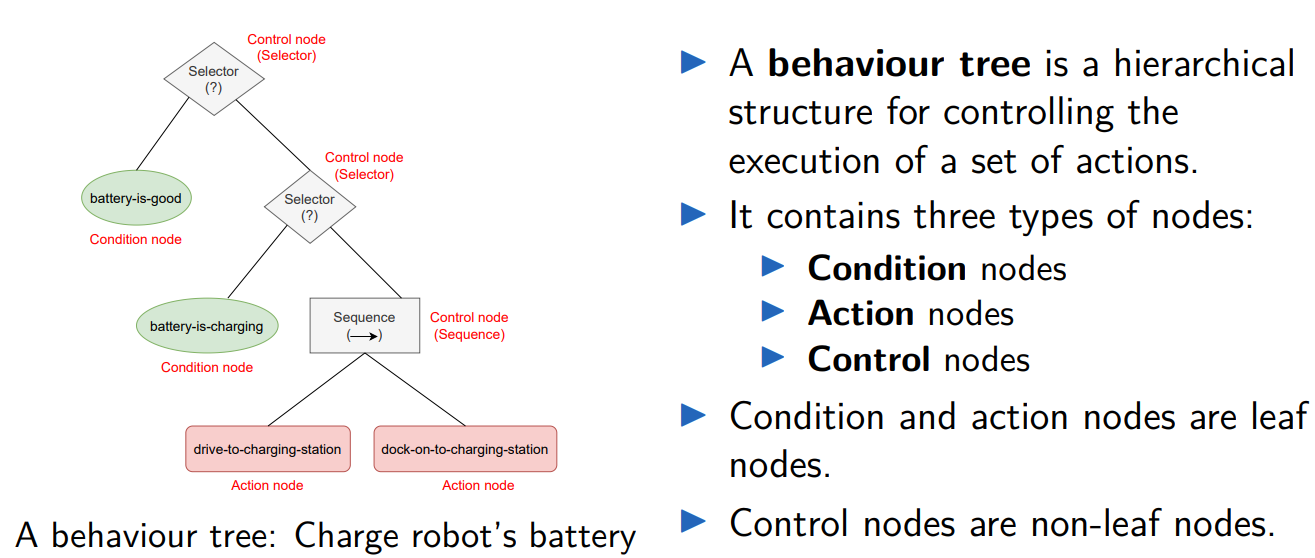
Behaviour Tree
Nodes
Condition node:
- Contains a Boolean-valued variable.
- Value of True indicates success.
- Value of False indicates failure.
Action node:
Contains an action to be performed by the agent (e.g. robot).
Action execution status: running, success, failure.
Selector
- Child nodes are executed one by one from left to right.
- The next child node is executed if and only if all the previous child nodes failed.
Status of a selector node:
If one of the child nodes is successful, then success.
If one of the child nodes is running, then running.
If all child nodes failed, then failure.
Similar to logical OR operation.
Sequence
- Child nodes are executed one by one from left to right.
- The next child node is executed if and only if all the previous child nodes were successful.
Status of a sequence node:
If one of the child nodes fails, then failure.
If one of the child nodes is running, then running.
If all child nodes are successful, then success.
Similar to logical AND operation.
Reactivity
- The status of a behaviour tree is checked at a specific frequency known as the tick frequency.
- Ticking begins at the root node and flows through the tree according to the logic of the control nodes.
- If the status of any condition nodes or action nodes has changed, then it can be detected in the next ‘tick’.
- Any change will automatically cause the ongoing actions to be aborted or other actions to be started, depending on the control logic encoded in the tree.
Additonal Infos
Link to original
Introduced by the gaming industry to model the behaviour of non-player characters. (NPC)
The following libraries have been used in robotics:
- BehaviorTree.CPP (written in C++)
- Source code: https://github.com/BehaviorTree/BehaviorTree.CPPDocumentation
- Documentation: https://www.behaviortree.dev/
- Used in the ROS 2 Navigation Stack (See here)
- py_trees (wirtten in Python 3)
- Source code: https://github.com/splintered-reality/py_trees
- Documentation: https://py-trees.readthedocs.io/en/devel/